2026年1月26日,英特尔正式放开了Panther Lake——即英特尔酷睿Ultra X处理器(系列3)的评测数据限制。
作为Intel 18A制程工艺打造的首个高性能移动级处理器,Panther Lake在RibbonFET全环绕栅极晶体管技术以及PowerVia背面供电技术加持下,实现了性能与能效的巨大突破。
同时,Panther Lake的GPU tile从Compute tile中分离出来之后,在核心规模上不仅变得更大,而且可以做更加灵活的配置,因此像本篇评测中酷睿Ultra X9 388H集成的12Xe核心的锐炫B390核显,将带来极其出色的GPU图形性能和AI算力表现。
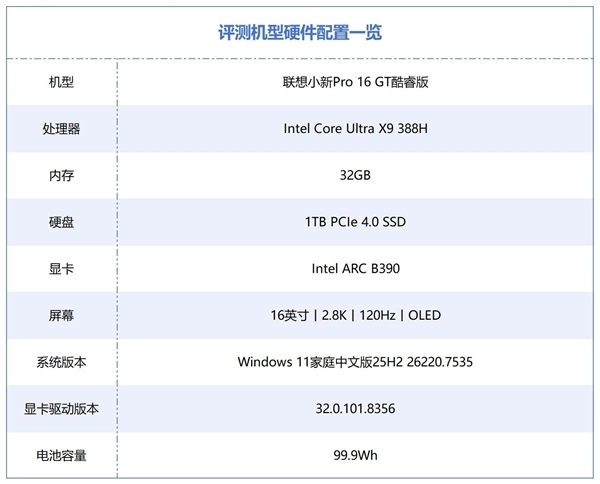
本次首发测试平台,我们使用了联想小新Pro 16 GT酷睿版机型,其具体配置如下:
架构简介
我们先来简单回顾一下Panther Lake的架构设计。
下图展示的是Panther Lake处理器的架构示意图,该处理器主要由三大模块构成。位于左上角的是Compute tile区域,这里集成了CPU的P-Core、E-Core与LP E-Core核心,负责图像信号处理的IPU 7.5计算单元,承担AI计算任务的NPU 5计算单元,以及Xe媒体和显示引擎。值得一提的是,该区域还包含了8MB的内存侧缓存单元,这是Panther Lake处理器新增的设计亮点。而所有的Compute tile均采用Intel 18A制程工艺制造而成。

左下角则是重新分离出来的Xe3架构锐炫核显,首发包含4核心和12核心两种规格,4核心GPU为Intel 3制程工艺打造,12核心GPU则采用了TSMC N3E制程工艺打造。
右侧紧挨Compute tile的平台控制模块同样采用外部代工,由TSMC N6制程工艺打造,其内部包含了所有I/O控制器。
其中8核心中央处理器(CPU)以及16核心CPU搭配12核心图形处理器(GPU)的处理器型号,均支持12条PCIe通道,具体由8条PCIe4.0通道与4条PCIe5.0通道组合而成;而16核心CPU搭配4核心GPU的处理器则配备20条PCIe通道,即包含8条PCIe4.0通道和12条PCIe5.0通道。除此之外,还升级配备了4个雷电4接口,集成了Wi-Fi 7(R2)和蓝牙Core 6.0控制模块,同时也包含2个USB 3.2接口控制模块与8个USB 2.0接口控制模块。
在平台控制模块的上方和下方,还设计有两块填充模块,它们不参与计算,主要负责配平整个Die,以使散热器的压力更加均衡,避免对整个Die造成损伤。
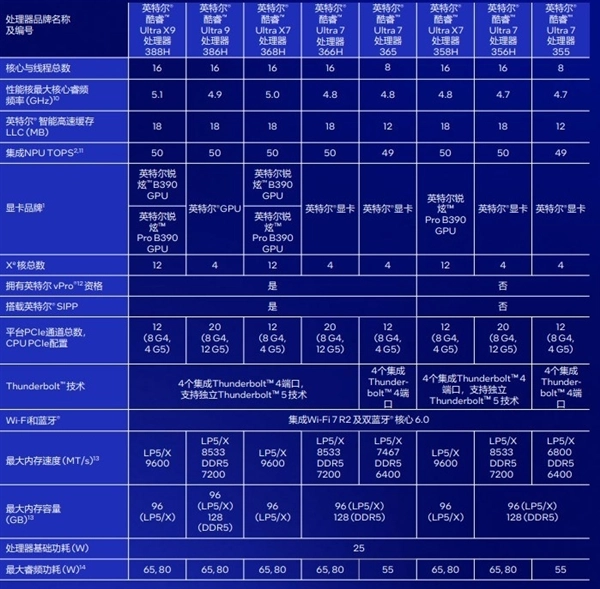
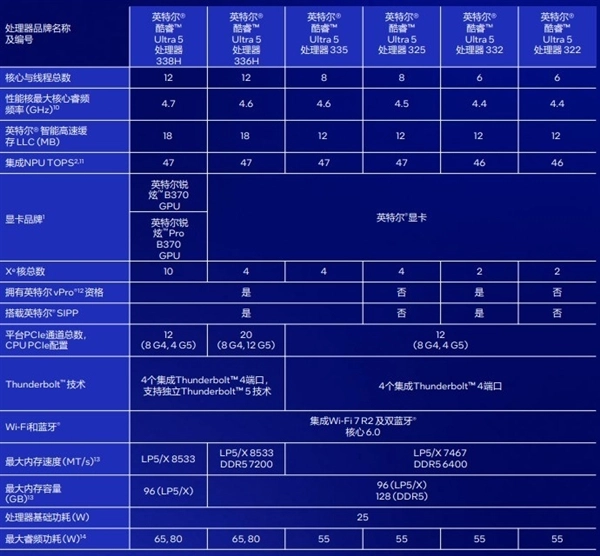
英特尔Panther Lake家族首发包含14款不同规格的SKU,最高型号为英特尔酷睿Ultra X9 388H和酷睿Ultra 9 386H,前者是我们今天评测的主角。
16核心16线程的CPU带来更强的计算能力,50 TOPS算力的NPU计算单元继续以低功耗赋能AI应用,而大放异彩的Xe3架构锐炫B390核显凭借12个Xe核心带来的强劲图形性能与120TOPS的AI算力升级,轻松覆盖游戏、创作到AI应用到全场景应用需求。
酷睿Ultra X9 388H性能评估
基本信息了解之后,我们正式进入测试环节。
首先来看英特尔酷睿Ultra X9 388H处理器的基本规格,它是一颗16核16线程处理器,性能核架构为Cougar Cove,能效核和低功耗能效核架构均为Darkmont,性能核睿频加速频率可以达到5.1GHz。
能效核与低功耗能效核的睿频加速频率分别是3.8GHz和3.7GHz,配备18MB L3缓存,基础TDP为25W,标称最高TDP达80W。我们测试的小新Pro 16 GT酷睿版,开启极客模式后能实现稳定85W的功耗释放。此外,Panther Lake的内存规格进一步升级,支持LPDDR5X 9600MT/s,最高可配备96GB双通道内存。

理论性能测试
下面我们来看看处理器的理论性能表现。
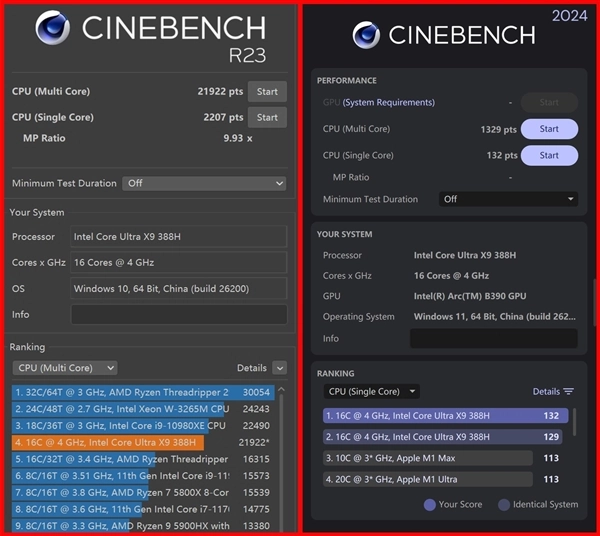
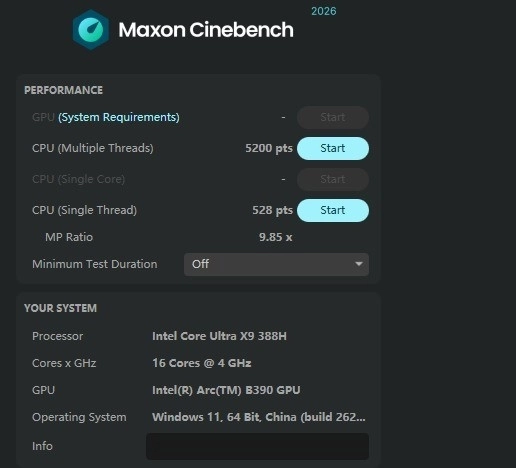
在单核和多核性能方面,我们主要参考CINEBENCH 2024的测试结果。但是R23和最新的2026的测试成绩同样也可以作为参考。
在CINEBENCH 2024测试体系中,酷睿Ultra X9 388H处理器的单核成绩为132分,多核成绩达1329分,展现出优异的性能表现。此外,在最新推出的2026测试标准下,该处理器的单核得分提升至528分,多核得分则达到5200分。后续我们还将逐步增加更多处理器的CINEBENCH 2026测试数据,以便大家能在新的测试标准下更直观地对处理器性能进行评估与比较。
其实从R23和2024单核和多核测试来看,酷睿Ultra X9 388H处理器与上一代酷睿Ultra 9 285H做对比的话(R23单核2015、多核21403,2024单核121,多核1147),已经实现了全面超越。
应用性能测试
理论性能方面,酷睿Ultra X9 388H处理器较上一代同级别酷睿Ultra处理器提升显著,这主要得益于新架构带来的性能升级。而单核和多核理论性能的进步,反映在实际应用层面会有怎样的表现?
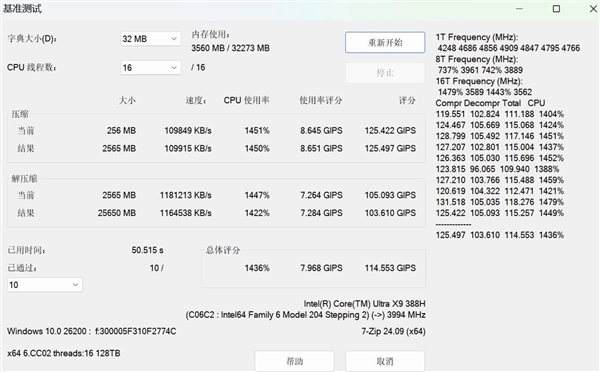
压缩/解压缩
首先是压缩和解压缩,7-Zip压缩速度109915 KB/s,解压缩速度1164538 KB/s,总评分114.553 GIPS,10轮压缩解压缩测试耗时仅50.515秒,速度极快。
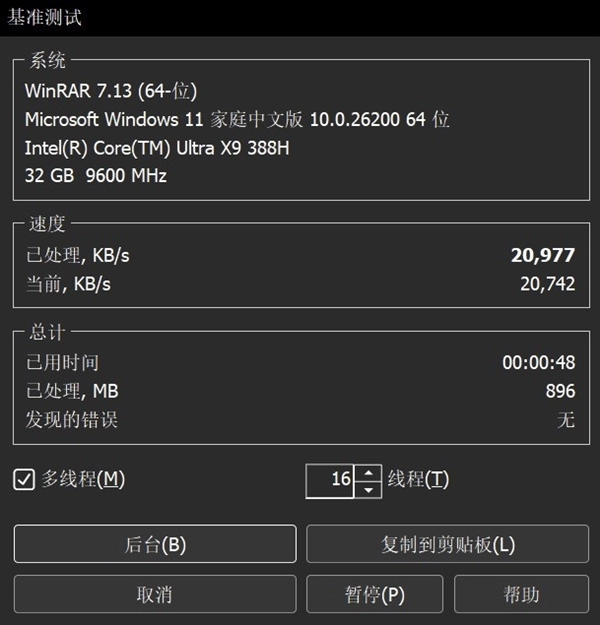
WinRAR压缩/解压缩基准处理速度平均达到了20977 KB/s,16线程带来的性能提升还是比较明显的。
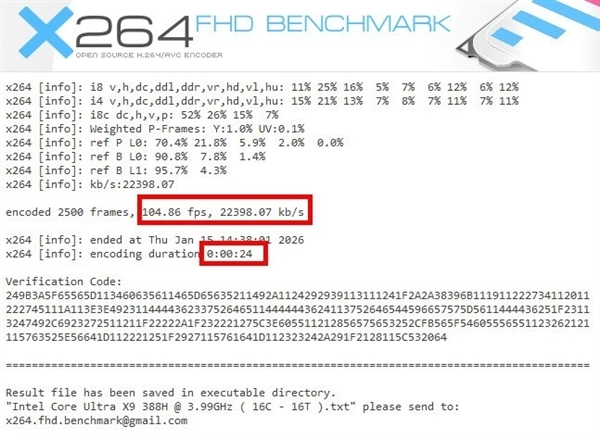
视频编码
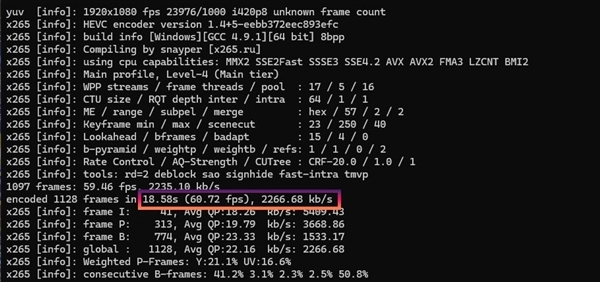
再来看看视频编码,这是英特尔酷睿处理器一直以来的强项。x264 Benchmark编码2500帧耗时仅为24秒,帧速率104.86fps;x265 Benchmark编码1128帧,耗时仅18.58秒,帧速率60.72fps,速度极快,是目前编码性能最强的移动级处理器。
渲染速率与采样率
渲染性能方面,我们参考V-Ray Benchmark、Corona 10 Benchmark以及Blender Benchmark的测试结果。
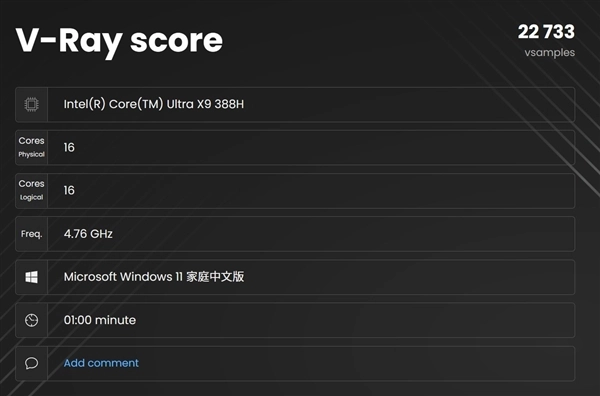
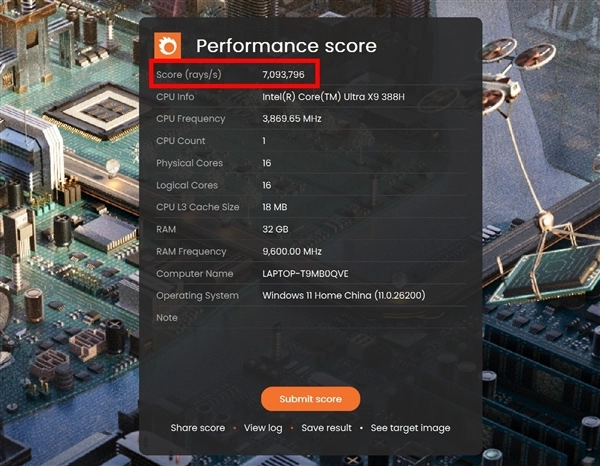
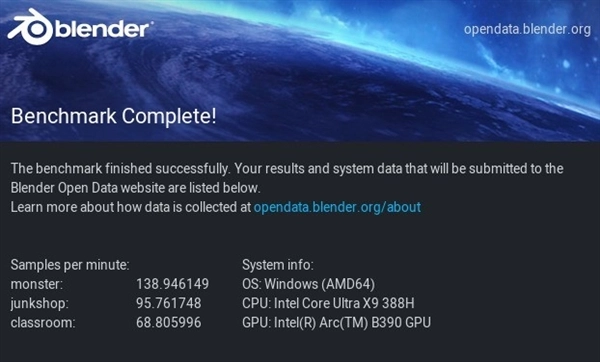
酷睿Ultra X9 388H处理器在V-Ray Benchmark测试中,一分钟采样率达22733 vsamples;Corona 10 Benchmark光线渲染速度为7093796 rays/s;Blender Benchmark的monster、junkshop、classroom三项测试里,1分钟采样率分别是138.94、95.76和68.8 samples,整体渲染性能较上一代有显著提升。
从英特尔自身定位来说,Panther Lake要达到的设计目标是拥有Arrow Lake性能的同时达到Lunar Lake的能效。而从CPU理论和应用测试来看,Panther Lake超额完成了性能目标,较Arrow Lake家族同级别的酷睿Ultra 9 285H性能更强,效率更快。
内存性能测试
除了CPU本身性能保持高水准之外,Panther Lake其实最让人期待的除了GPU性能,还有内存。毕竟LPDDR5X 9600MT/s规格的支持是目前移动级处理器中的独一档,那么实际性能如何呢?
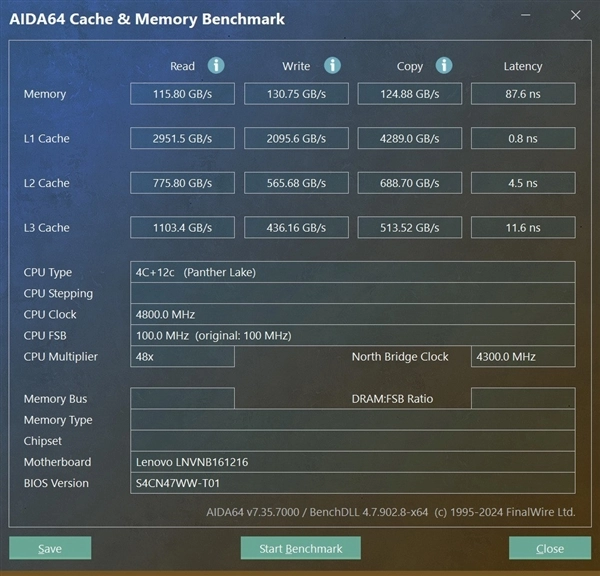
从AIDA 64内存性能测试来看,读取速度达到了115.8 GB/s,写入速度130.75 GB/s,拷贝速度124.88GB/s,这意味着从Panther Lake开始,移动级平台的内存性能全面突破百GB/s速度大关。
而且更为让人意外的是,内存延迟降到了87.6ns,这可以说是相当大的进步。因为此前几代处理器平台在内存延迟上普遍超过了100ns,Panther Lake内存延迟下降到87.6ns可以说是非常大的进步,在面对游戏等内存敏感型应用上,更低的延迟自然会带来更好的体验。
锐炫B390核显性能评估
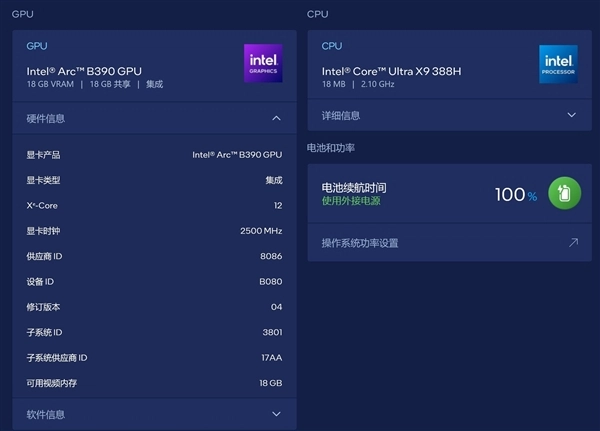
酷睿Ultra X9 388H处理器集成了锐炫B390核显,拥有12个Xe核心,可用显存为18GB,显存频率2500MHz,这可以说是英特尔目前为止最强的核显。而且因为GPU tile从Compute tile中分离出来,后续在核心规模的调配方面自然会更加灵活。
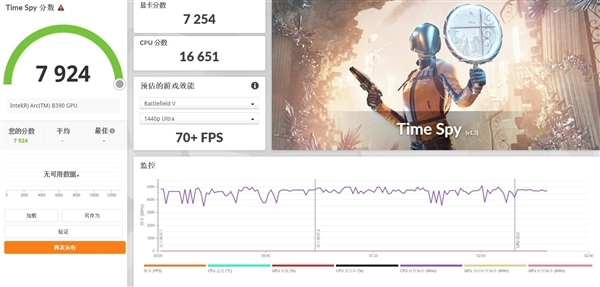
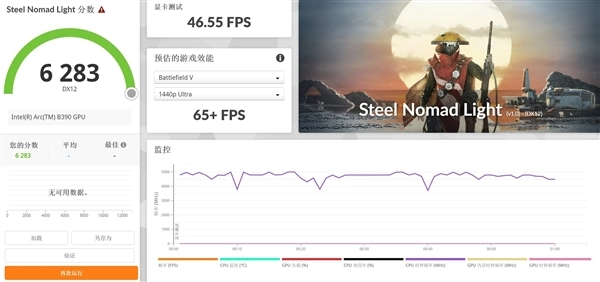
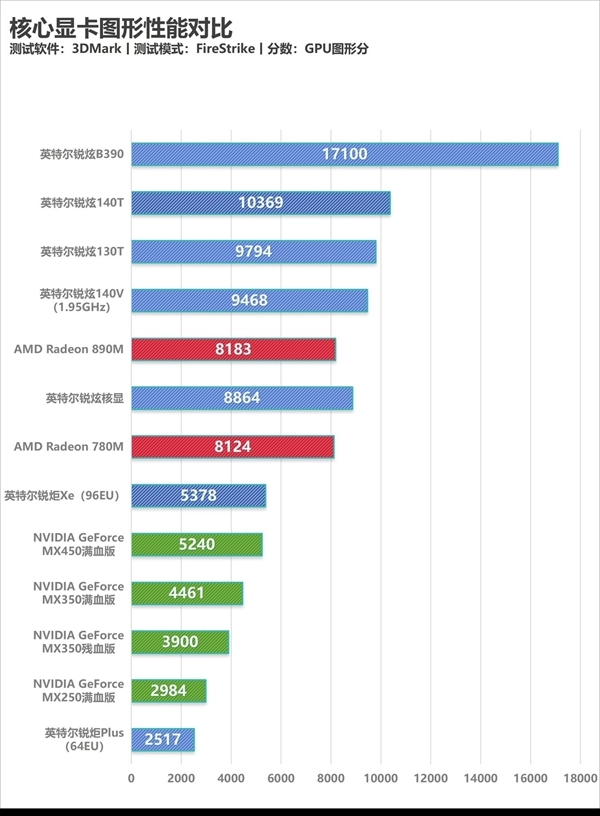
我们先来通过3DMark理论测试看看锐炫B390的图形性能表现。在Time Spy DX12测试标准下,B390图形性能评分达到了7254分,这个性能其实比较接近此前65W超低功耗的RTX 4060独显的性能水准。另外Steel Nomad Light测试得分6283分,在集成显卡里确实是有着天花板级别的图形性能表现。
下图是3DMark FireStrike模式历代核显的测试成绩,大家可以此为参考对锐炫B390的性能有一个更为直观的了解:
检验GPU性能最直接的方法还是游戏,所以接下来我们看看锐炫B390的实际游戏体验到底怎样?
为了有一个比较具象的感知,我先贴一张上一代锐炫140V核显的《CS2》1920 x 1200分辨率、默认画质、沙漠2地图的平均帧数,只有50fps。算是勉强能玩,但肯定是达不到电竞要求的。
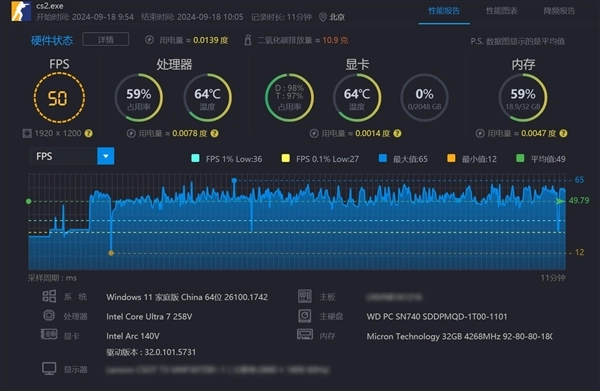
图形性能大幅提升的锐炫B390可就完全不一样了,1920×1200分辨率、低画质可以直接上到292.8fps,游戏性能提升显著。
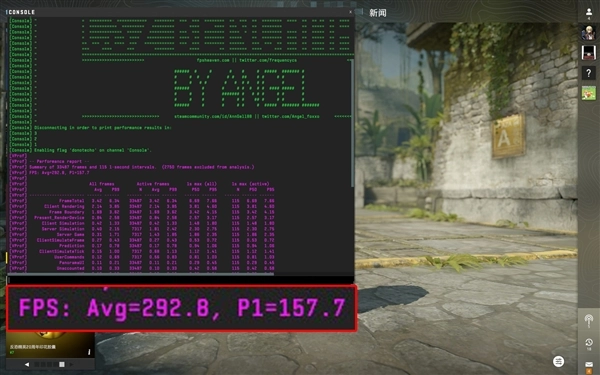
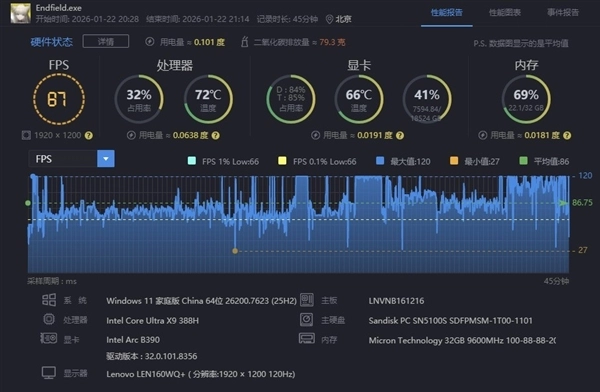
《明日方舟:终末地》是刚刚上线的一款3D即时策略RPG游戏,画面制作精良,对硬件性能要求是比较高的。在1920×1200分辨率,开启最高画质的情况下,锐炫B390核显运行游戏的平均帧率为87fps,流畅运行无压力。

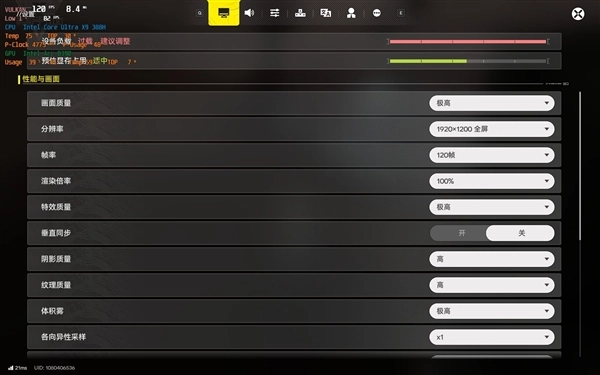
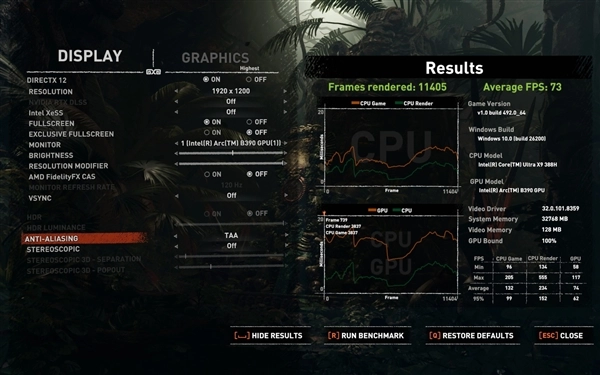
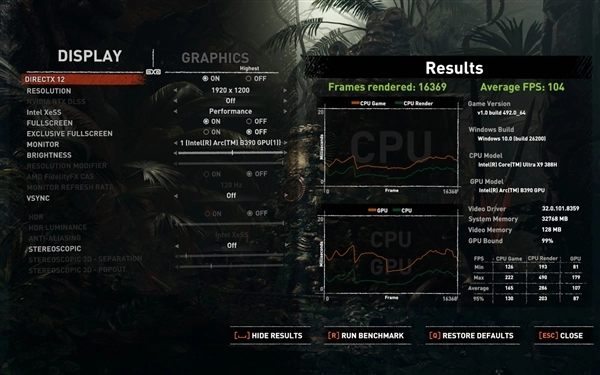
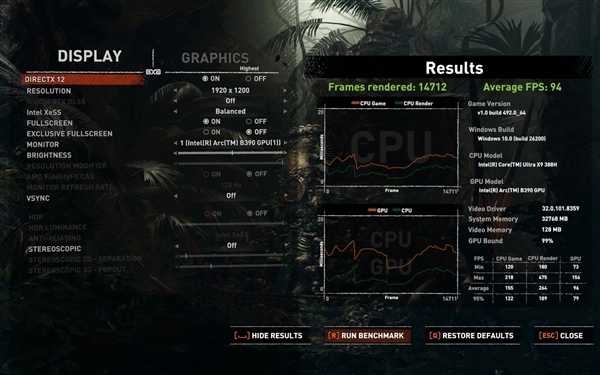
我对《古墓丽影:暗影》这款游戏进行了XeSS开关状态的测试,情况如下:当游戏设置为1920×1200分辨率与最高画质时,关闭XeSS功能后,平均帧率达到73fps;而开启XeSS的性能、平衡、画质、超高画质这四个档位后,在相同的1920×1200分辨率和最高画质条件下,平均帧率依次为104fps、94fps、87fps、77fps。由此可见,运行这类推出时间稍早的3A游戏是完全没有压力的。
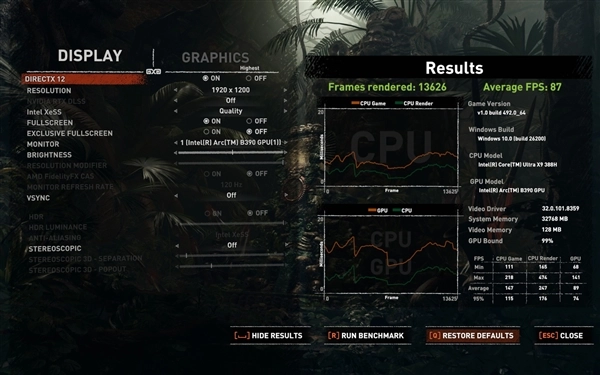
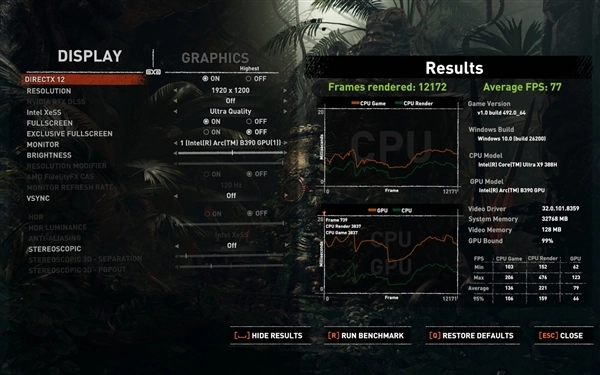
《极限竞速:地平线5》对于硬件的优化非常到位,所以锐炫B390跑起来也是相当顺畅,1920×1200分辨率,极端画质下,平均流畅度可以达到64fps,这对于集成显卡来说已经是相当出色的表现了。

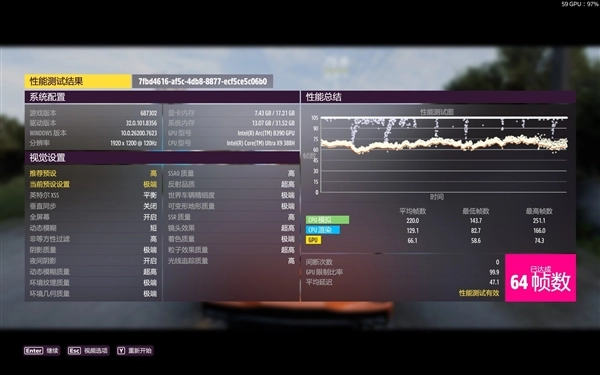
《荒野大镖客2》在1920×1200分辨率默认画质下进行测试,最终平均帧率达到了80fps,可见12个Xe核心的锐炫B390在游戏性能上确实给力。

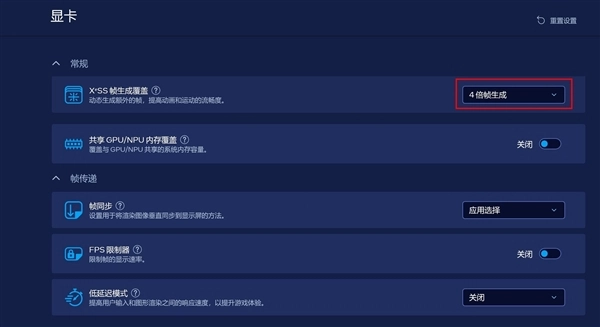
另外Xe3架构核显开始支持多帧生成技术,在Intel Graphics Software控制中心里最高可以开启4倍多帧生成,这样的话在运行3A游戏时就会有相当不错的帧率表现。而且如果把锐炫B390放到掌机里的话,游戏体验绝对是秒杀现在所有的Windows掌机了。
我们通过《赛博朋克2077》和《黑神话:悟空》进行了多帧生成测试,可以看到《赛博朋克2077》在1920×1080分辨率、低画质下平均帧率可以达到264.79fps;而如果关闭游戏内帧生成选项的话,1920×1080分辨率、低画质下平均帧率也能达到106.13fps,表现相当不错。
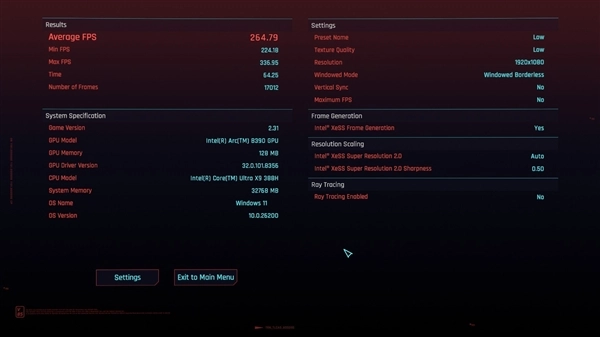
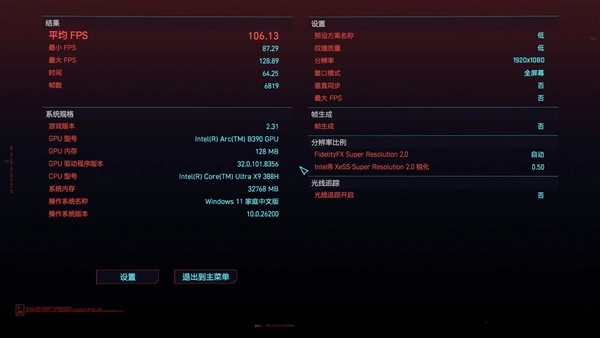
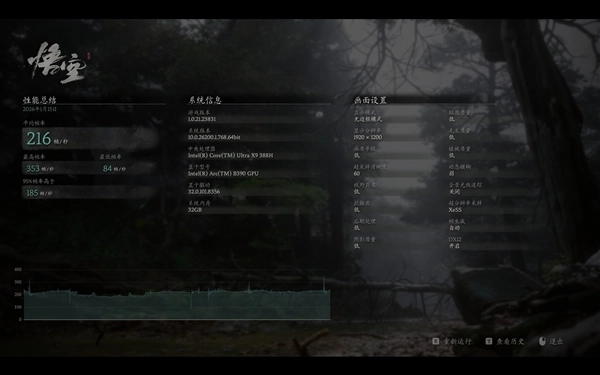
《黑神话:悟空》在1920×1200分辨率、低画质,开启4倍多帧生成的情况下,平均帧率可以达到216fps,而且《黑神话:悟空》这款游戏对于GPU性能的敏感度极高,因此可以充分体现出这一代锐炫B390核显的图形性能到底提升有多大。
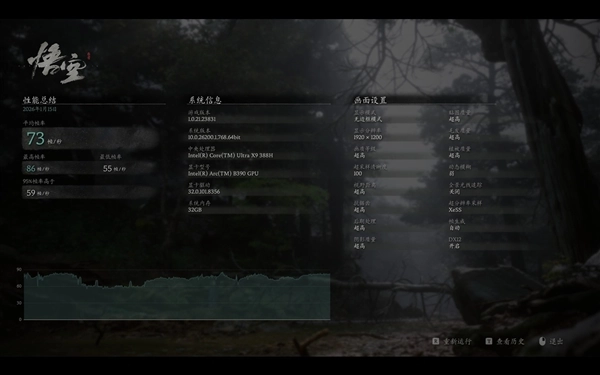
另外,要是用锐炫B390玩游戏,在1920×1200分辨率下其实不用太保守地开低画质。我们把画质调到超高档——也就是仅次于影视级的第二档高画质,锐炫B390运行《黑神话:悟空》的平均帧率能达到73fps,完全能满足动作类3A游戏的流畅运行要求。而且放大图片可以看到,95%帧率都高于59fps,画面流畅度特别稳定,不会出现瞬时大幅掉帧带来的迟滞或卡顿问题。
通过游戏测试可以看出,锐炫B390核显性能着实是相当不错,1080p分辨率下基本所有游戏都能带来相当不错的画面流畅度,而2.5K分辨率则可以通过降低画质或者开启XeSS以及多帧生成来提高游戏帧率。
相当出色的生产力
比Arrow Lake更强的CPU性能,比上一代锐炫核显更强的图形性能,以及大幅进步的内存读写速度与延迟降低之外,酷睿Ultra X9 388H在生产力方面会带给用户怎样的体验呢?
生产力理论性能方面,我们参考PCMark 10 Extended测试。
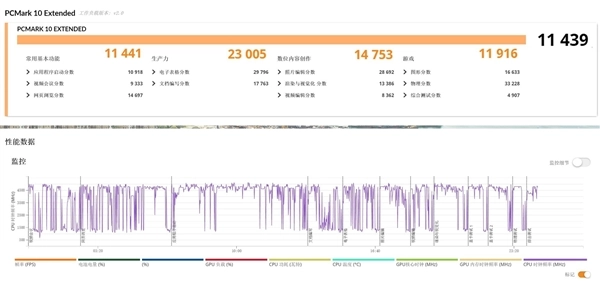
搭载酷睿Ultra X9 388H平台的联想小新Pro 16 GT酷睿版在常用基本功能,包含Web浏览、视频会议、应用程序启动等得分为11441分。
说明其完成这些基础办公任务没有任何问题;生产力项目测试中得分高达23005分,表明其拥有卓越的电子表格、文档工作性能;数位内容创作评分高达14753分,说明其能够非常高效地完成图片、视频编辑、图形渲染等工作;游戏性能评高达11916分,游戏体验出色。
综合得分11439分,是目前轻薄本产品中,PCMark 10 E模式得分最高的一款,而且四项测试分数均过万,可见酷睿Ultra X9 388H是相当完美的一款移动端处理器平台。
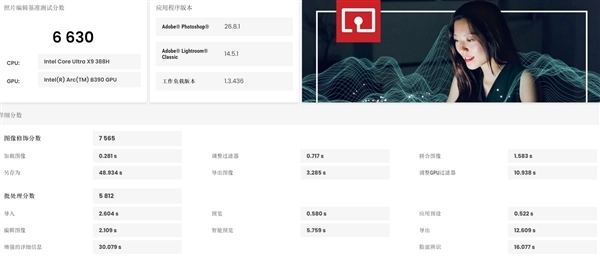
生产力应用性能方面,参考UL Procyon的照片编辑和视频编辑测试,联想小新Pro 16 GT酷睿版的评分分别达到了6630和16704分,可以轻松胜任RAW图片处理以及1080p、2K、4K视频剪辑任务。
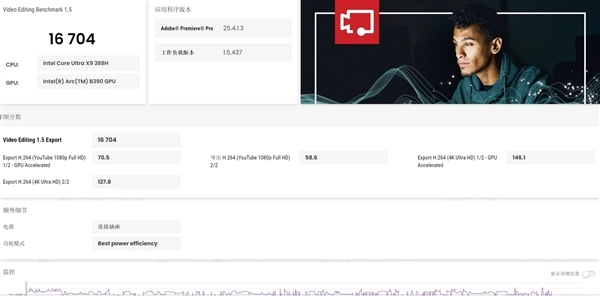
综合来看,英特尔酷睿Ultra X9 388H在生产力性能方面相对于上一代Arrow Lake有着非常显著的提升,尤其是GPU性能大幅加强之后,图片与视频处理都更加游刃有余,即便将竞品平台考虑进来,酷睿Ultra X9 388H也是目前最强的移动级处理器平台。
AI算力评分
Panther Lake除了在传统计算领域有着大幅度提升之外,更加强调AI计算能力的升级。其CPU+NPU+GPU算力达到了180TOPS,其中GPU算力提升最大,达到了120TOPS,而NPU虽然只提升了2TOPS,但是其矩阵引擎规模变大之后,实际计算效率远比纸面的2TOPS更高。
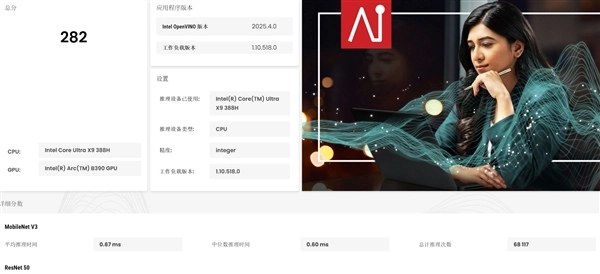
通过UL Procyon,我们给CPU、GPU和NPU算力进行了测算,首先CPU Integer算力评分为282,相对于上一代没有提升。
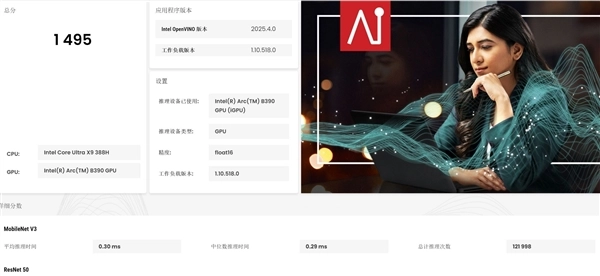
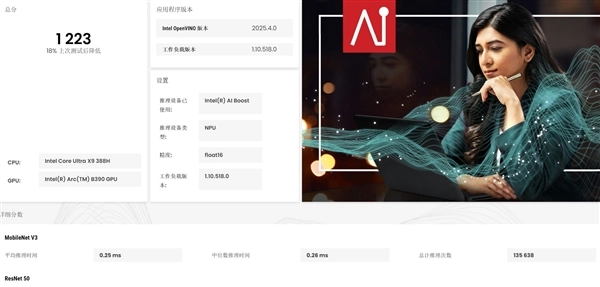
而GPU Float16算力评分达到1495,相对于上一代的800+提升了近700分;而NPU算力评分达到1223,相对于上一代900+的评分提升了300多分,因此酷睿Ultra X9 388H在GPU和NPU算力上分别提升了约78%和32%!
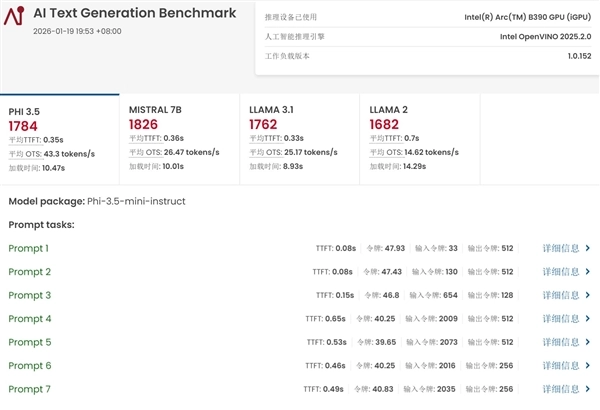
另外,上一代核显由于算力和显存的双重限制,无法完成UL Procyon的AI大语言模型生成测试;而酷睿Ultra X9 388H不仅能顺利通过该测试,在PHI 3.5、MISTRAL 7B、LLAMA 3.1、LLAMA 2这四款大语言模型的测试中,其生成速度还分别达到了43.3 tokens/s、28.47 tokens/s、25.17 tokens/s和14.02 tokens/s。
轻松达成全天候续航
性能过硬,那么续航如何呢?
UL Procyon1小时视频播放掉电量只有3%,相比上一代Lunar Lake的9%左右提升显著。
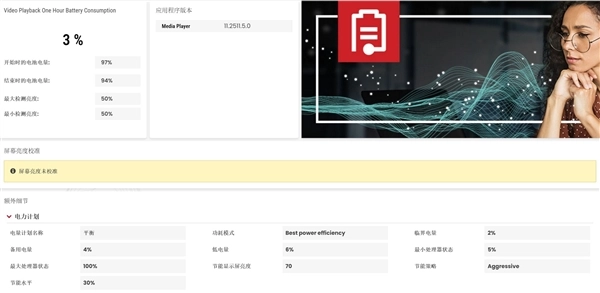
另外笔者还通过B站4K视频循环播放进行了续航测试,并且使用Windows 11系统自带的电池电量监测查看续航表现。这项测试对笔记本电脑的续航挑战极大,因为不仅需要强有力的硬件解码能力,同时无线网络还始终处于工作状态。测试时我们将屏幕亮度调整至50%,刷新率切换到60Hz,开启节能模式,音量调整到30%。
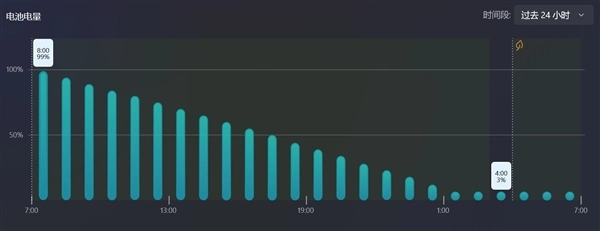
可以看到从第一天早8点开始循环播放时电量为99%,到第二天凌晨4点左右电量剩余3%自动进入休眠,历时约20个小时,表现相当出色。
功耗释放稳定双拷机温度低
最后我们来看看酷睿Ultra X9 388H的功耗释放和温度表现。这里需要说明的一点是,我们使用的测试机并非零售版机型,而是工程样机,因此最终的散热表现可能会有再进一步的改善。
首先AIDA 64 FPU CPU单拷机测试,CPU功耗稳定85W释放,CPU封装温度96℃,表现良好。
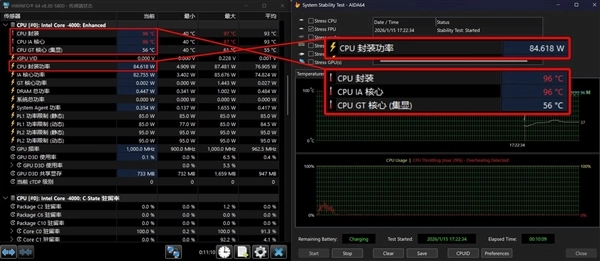
AIDA 64+FurMark CPU+GPU双拷机测试,CPU封装功率依旧稳定在85W,此时整体封装温度会下降到84℃,所以在日常使用的时候完全无需担心温度问题。
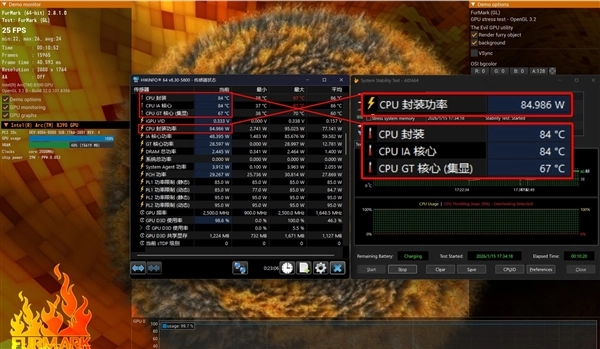
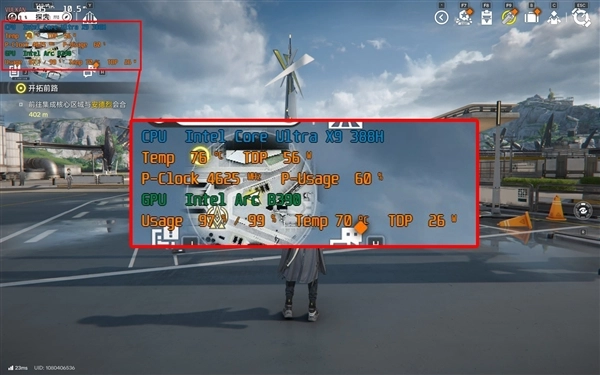
就比如在玩《明日方舟:终末地》的时候,我们通过监测软件记录了CPU和GPU的实时温度,分别为76℃和70℃,整体功耗在82W左右,散热无压力,且功耗释放充分。
联想小新Pro 16 GT酷睿版简介
评测的最后,我们看看本次评测所使用的测试平台,也就是联想小新Pro 16 GT酷睿版的设计。因为使用的是工程样机,所以可能最终设计会略有不同,因此以实际上市产品为准。
工程样机其实和去年的小新Pro 16 GT AI元启版一样,简约干练的家族式设计语言,深空灰配色加上金属喷砂漆面,塑造出细腻的金属质感与触摸手感。A面正中间位置镶嵌有亮面抛光的Lenovo品牌logo,为整体的简约设计增添了些许时尚感。

这款机器配备了16英寸SSR星耀舒适屏,默认600nits、HDR开启后峰值1100nits的亮度将高色域、高色准优势凸显出来。而且这一亮度等级在目前的笔记本市场里罕有对手。
这块屏幕通过了严苛的VESA Display HDR TrueBlack 1000认证,四边超窄边框OLED大屏有着高达90%的屏占比,支持2880×1800分辨率,16:10黄金比例为生产力应用带来极为出色的视觉体验。它还支持60Hz/120Hz刷新率切换,支持莱茵硬件级低蓝光/无频闪认证。
其机身重量大约为1.7kg,对比市面上其它品牌的16英寸笔记本电脑要更轻便一些。

底部开有大面积散热窗,内置双风扇散热模组,确保整体的散热效率。

整个C面同样给人以简约、干练的印象。全尺寸白色背光键盘采用了1.5mm键程设计,手感舒适,独立数字键区必须给个好评!硕大的触控板位于空格键正下方,操控起来极为顺滑。方向键并未采用半高设计,足见联想在设计产品时极为关注用户需求,避免了不少雷点。标志性的Fn+Q性能模式快速切换功能延续下来。
另外可以看到因为是工程样机,所以C面腕托区域并未贴英特尔第三代酷睿Ultra处理器的硬件标识,实际上市产品会贴。


小新Pro 16 GT酷睿版提供了大满贯接口,有着出色的扩展性。机身左侧双满血雷电4接口同时可以满足数据高速传输、视频输出、PD充电的需求,标准的HDMI 2.1视频端口方便外接屏幕。

机身右侧的2个USB 3.2 Gen 1 Type-A使用便捷,标准SD读卡器相比不少产品配备的MicroSD读卡器更加实用。另外电源键设计在侧面的话,外接显示器就会更加方便,开机时不用打开屏幕。

总结
通过一系列深入测试可以看到,首个Intel 18A制程工艺打造的Panther Lake处理器可以说是交出了一张完美答卷。
这颗酷睿Ultra X9 388H在CPU、GPU、NPU性能上没有短板。映射在实际应用端的话,从生产力办公,到游戏,再到AI等常见应用都可以提供极为出色的性能体验。
同时其在能效方面表现突出,搭配大容量锂电池可以达成超过24小时以上的续航能力。而且在实际应用中,4K网络流媒体连续播放续航达到20小时左右,这意味着长续航不再是ARM+MacOS阵营的独有优势,英特尔第三代酷睿Ultra处理器让x86+Windows阵营也有了超长续航能力。
然而可以预见的是,基于酷睿Ultra X9 388H打造的新一代轻薄本或AI PC的价格并不便宜,尤其是在内存、硬盘等配件集体涨价的情况下,酷睿Ultra X9 388H机型面临的销量压力着实不小。
而从目前第三代酷睿Ultra家族的构成来看,笔者个人预计酷睿Ultra 5 338H,也就是搭载10个Xe核心的锐炫B370核显的处理器,更大概率会成为销量甜点。
因此,如果单从Intel 18A制程,以及酷睿Ultra X9 388H处理器自身各种性能、能效表现来看的话,这绝对是有史以来最完美的一颗移动端PC处理器。

奥特曼王者传奇安卓免费版
类型:策略塔防
查看



 下一站江湖2里李三问在什么地方
下一站江湖2里李三问在什么地方
 海狮与海豹之间最主要的差异体现在哪些方面呢?
海狮与海豹之间最主要的差异体现在哪些方面呢?
 星露谷物语中玛鲁的好感度相关事件都包含哪些内容
星露谷物语中玛鲁的好感度相关事件都包含哪些内容
 下一站江湖2大雪山晋升攻略
下一站江湖2大雪山晋升攻略
 王者荣耀世界里的燃山回响这个玩法是否有趣
王者荣耀世界里的燃山回响这个玩法是否有趣
 空洞骑士丝之歌里武器要去哪里升级
空洞骑士丝之歌里武器要去哪里升级
 火影忍者手游里新希的技能要怎么了解呢
火影忍者手游里新希的技能要怎么了解呢
 燕云十六声七级家业的通关攻略
燕云十六声七级家业的通关攻略
 地牢战争3第十一关通关指南
地牢战争3第十一关通关指南
 下一站江湖2流风回雪剑的获取方式是什么
下一站江湖2流风回雪剑的获取方式是什么








