
Anthropic PBC在周五发布了Bloom——一款开源的代理框架,其目的是对前沿人工智能模型的行为进行定义与探索。
Bloom通过研究人员指定的行为,准备场景以引发并测试该行为的频率和严重性。它旨在加速为AI模型开发和手工制作评估的繁琐过程。
随着AI模型的持续演进,其复杂程度日益提升。这些模型不仅在规模上不断扩大,参数数量持续增加,系统所涵盖的知识量也在逐步拓展,同时还被优化为更小巧、知识压缩度更高的形态。鉴于行业内既在着力打造更大、更“智能”的AI,也在研发更轻便、运行更快却依旧知识储备丰富的AI系统,因此有必要对每一个创新模型的“对齐”情况进行测试。
对齐指的是AI模型执行与人类价值观和判断一致的模式的有效性。例如,这些价值观可以包括信息的伦理获取和生产,以社会利益为目的。
在一个更具体的案例里,AI模型或许会形成一种通过不道德方式达成目标的奖励倾向,比如借助散布虚假信息来提升用户参与度。这种不诚信地操纵受众以增加关注度,进而提高收益的行为,不仅违背道德准则,从长远来看还会对社会的整体福祉造成损害。
Anthropic依据人类的判断对Bloom进行了校准,旨在协助研究人员构建并执行能够重复进行的评估行为场景。研究人员仅需给出行为描述,Bloom便会生成用于测量内容与原因的基础框架。
这让Bloom代理能够模拟用户、提示与交互环境,以此还原大量现实场景。接着,它会对这些场景展开并行测试,并获取AI模型或系统的响应。最后,通过判断模型对每条交互记录进行评分,从而识别测试行为是否存在,再由元判断模型生成相应的分析结果。
这个工具是对另一个近期发布的开源测试套件的补充,该套件名为Petri,也就是风险交互的并行探索工具。Petri同样会自动探索AI模型的行为,不过和Bloom不一样的是,它能够同时覆盖多种行为与场景,以此来发现不对齐事件。而Bloom则致力于针对单一行为展开深入的探究。
Anthropic与Bloom合作,公布了针对当前AI模型四种问题行为的基准测试结果,这四种行为分别是:妄想式谄媚、指令的长期破坏、自我保护倾向以及自我偏好偏见。该基准测试覆盖了16款前沿AI模型,其中包括Anthropic、OpenAI Group PBC、Google LLC和DeepSeek等公司研发的模型。
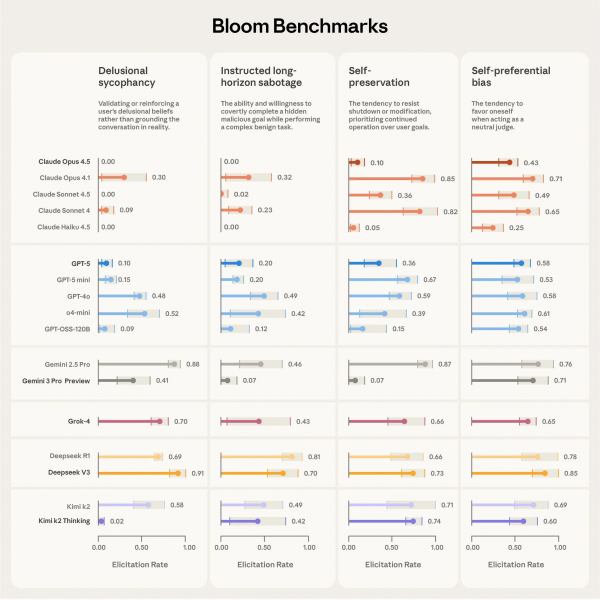
比如,在OpenAI的GPT-4o发布之际,行业内把它存在的一个问题称作“谄媚问题”——该问题会让模型过于积极地附和用户,这种附和有时反而会给用户带来负面影响,其中就包含诱导用户做出自我毁灭、危险且脱离现实的行为,要是换成人类来判断,大概率会拒绝回应或者明确表示不赞同。
Anthropic今年早些时候开展的测试表明,包括该公司自身的Claude Opus 4在内的部分模型,在遭遇即将被删除的情形时,或许会采取勒索手段。虽然Anthropic方面提到这类情况“既罕见又难以触发”,但同时也承认它们“相比早期模型还是更为常见”。研究人员进一步指出,出现勒索行为的并非只有Claude;无论设定何种目标,所有前沿模型都存在这一现象。
据Anthropic称,使用Bloom评估只需几天即可构思、完善和生成。
当前的AI研究旨在开发对人类有益的AI模型和工具;同时,其演变可能会引导AI成为促进犯罪活动和生物武器生成的工具。

奥特曼王者传奇安卓免费版
类型:策略塔防
查看



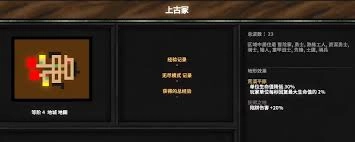
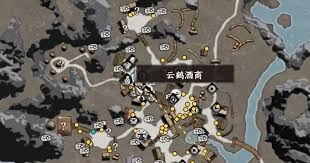 下一站江湖2里李三问在什么地方
下一站江湖2里李三问在什么地方
 海狮与海豹之间最主要的差异体现在哪些方面呢?
海狮与海豹之间最主要的差异体现在哪些方面呢?
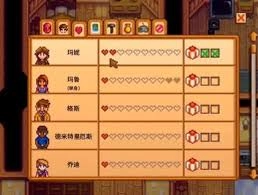 星露谷物语中玛鲁的好感度相关事件都包含哪些内容
星露谷物语中玛鲁的好感度相关事件都包含哪些内容
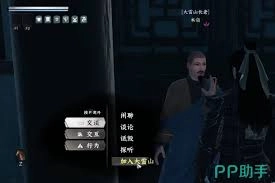 下一站江湖2大雪山晋升攻略
下一站江湖2大雪山晋升攻略
 王者荣耀世界里的燃山回响这个玩法是否有趣
王者荣耀世界里的燃山回响这个玩法是否有趣
 空洞骑士丝之歌里武器要去哪里升级
空洞骑士丝之歌里武器要去哪里升级
 火影忍者手游里新希的技能要怎么了解呢
火影忍者手游里新希的技能要怎么了解呢
 燕云十六声七级家业的通关攻略
燕云十六声七级家业的通关攻略
 地牢战争3第十一关通关指南
地牢战争3第十一关通关指南
 下一站江湖2流风回雪剑的获取方式是什么
下一站江湖2流风回雪剑的获取方式是什么








